1. 问题
这是Google大神Jeff Dean在2013年的时候发表的一篇文章,主要是为分布式系统中一个复杂而重要的问题提供了一整套的解决方案,这个问题就是:
当用户的请求依赖大规模分布式系统来协作完成时,如何保证请求的响应时间?
2. 为什么
首先,为什么要保证用户请求的响应时间?因为对于某些使用场景来说,只有当响应时间控制在百毫秒以内,用户才能感觉到系统是流畅的,例如Google的搜索框会随着用户的输入不断地提示用户可能之后输入的内容,试想如果这个提示需要一秒的时间才能出现?那用户体验是会大打折扣的。
其次,什么是大规模分布式系统?
举例来说,当用户打开亚马逊购物网站的一个商品信息页时,可能需要从底层数百个子服务来获取信息,而这些子服务还有它们依赖的更基础的服务,这意味着一个用户的请求可能需要数千台服务器协同工作才能完成。
在这样的集群规模下,即使有极少数机器请求响应时间较长,也有很大的概率导致用户请求的响应时间变长,如下图所示:
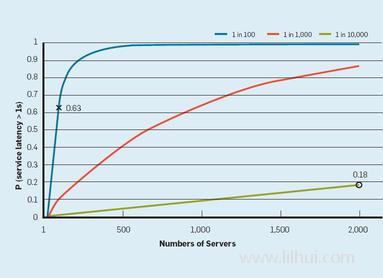
当用户请求需要100台服务器来协同完成时,假设只有 1% 的调用延迟较大,那用户请求受影响导致响应时间较长的概率为0.63(1 - 0.99 ** 100)
当用户的请求需要2000台服务器来协同完成时,假设只有 0.01% 的调用延迟较大,那用户请求受影响导致响应时间较长的概率为0.18(1 - 0.9999 ** 2000),相当于每5个用户就有一个体验不佳
在实际生产环境中,有多种原因导致服务调用的响应时间变长,如:
- 在一台机器上可能同时部署了多个服务,这些服务可能会对于如CPU,内存,网络等多种资源进行竞争,导致某个服务的响应时间变长;
- 某些后台运行的线程(假设每个小时运行一次),可能会在运行时占用一些系统资源(如磁盘IO)导致这台机器上的服务响应时间变长;
- 在分布式环境下, 当多个服务对共享资源(如分布式文件系统等)产生竞争时,也会导致服务的响应时间变长;
- 其他的原因还包括请求排队、垃圾回收、日志压缩等;
Jeff Dean的想法是,既然可以在不可靠的服务器上实现可靠的分布式存储系统,那利用同样的想法,我们也可以在响应时间有突刺的服务器集群上实现响应时间快速且一致的分布式集群,他把这样的系统叫做Tail-Tolerant。
3. 怎么做
3.1 单个模块的响应时间
这一部分讨论的是如何实现一个模块对外的每一次响应的时间是快速一致的,这部分不是本文的重点,因此简单带过。
作者列举了一些基本的方法,如:
- 不要在底层设置太长的任务队列,而由上层基于任务的优先级进行动态的下发。例如Google的集群文件系统,在磁盘的IO队列上只有维护一个很短的队列,当应用层有优先级更高的任务的时候,可以及时将这些任务下发,以保证这些高优先级任务的快速响应;
- 将需要长时间运行的任务拆成多个短时间运行的任务。这个跟上面做法的逻辑一样,就是为了防止一个任务长时间占用系统资源而导致其他任务响应时间变长;
- 控制好定时任务和后台运行的任务。具体做法有,将后台的大任务拆分成一系列的小任务,在后台任务运行的时候首先确认系统的负载,如果负载太高,则延迟运行后台任务等。
尽管我们可以通过各种做法让一个模块的响应时间变得更快更均匀,然而由于大规模分布式系统的复杂性,实际上根本无法做到完全消除单个模块的响应时间出现突刺,因此接下来讨论在更大的层面如何解决这个问题。
3.2. 服务间调用控制
这一部分讨论在一个服务调用另一个服务时,可以通过什么技巧来解决响应时间出现突刺的问题。
首先,分布式系统为了解决数据可靠性的问题,通常将数据复制到多台服务器上,同时为了实现服务的高可用,又会有多个服务器提供同样的功能,防止部分服务器出现故障。
为了解决响应时间出现突刺,调用者需要将请求“同时”发送给多台服务器,并在收到最快的响应之后,马上终止其他服务器的处理(或将其他服务器返回的结果直接丢弃)。采用这种方法,可以大大降低某个调用出现突刺的情况,因为所有的服务器都出现突刺的概率会大大降低。同时我们也可以看到,这样会让整个系统的请求数量翻两倍或三倍。
因此,论文给出的做法是:
- 客户端首先发送一个请求给服务端,并等待服务端返回的响应;
- 如果客户端在一定的时间内没有收到服务端的响应,则马上发送同样的请求到另一台(或多台)服务器;
- 客户端等待第一个响应到达之后,终止其他请求的处理;
上面“一定的时间”定义为:95%的请求的响应时间。
Google的测试数据表明,采用这种方法,可以仅用2%的额外请求,将系统99.9%的请求的响应时间从1800ms降低到74ms:
For example, in a Google benchmark that reads the values for 1,000 keys stored in a BigTable table distributed across 100 different servers, sending a hedging request after a 10ms delay reduces the 99.9th-percentile latency for retrieving all 1,000 values from 1,800ms to 74ms while sending just 2% more requests.
以上这种做法被称为 Hedged Request,下面介绍另一种解决问题的办法,称为 Tied Request。
分布式系统中存在一种情况,即请求排队,特别地,可能出现请求的排队时间比处理时间更长的情况。
当一个上游系统向下游系统分发请求时,一个比较合理的做法是将请求分发给任务队列较短,负载较轻的服务器。
Google推荐的做法是,上游系统同时发送两个一样的请求给下游多个服务器,当下游服务器处理完成后,通知其他服务器不用再处理该请求。为了防止由于任务队列为空而导致的所有服务器同时处理任务的情况,上游系统需要在发给下游多个系统的时候引入一个延迟,该延迟时间要足够第一个系统处理完任务并通知其他系统。
此处有一个重要的思考:为什么上游系统不再发送请求给下游时首先进行探测,查看各个下游服务器的任务队列长度,然后再将请求发送给任务队列最短的服务呢?
原因有三:
- 探测和发送请求之间有一段时间间隔,即在探测之后再发送请求时,各个服务器的负载已经发生了变化
- 如果很多客户端同时发现某个服务器负载较低,则可能同时将请求发给该服务器,导致该服务器瞬间过热
- 仅通过队列长度来估计处理时间未必准确,即任务队列端不一定真的负载低
以上两个技巧不仅仅可以用于简单的数据查询服务,例如基于Reed-Solomon编码的存储系统,第一个请求可以去某台服务器上查询数据,如果在一定时间内数据未查到,则可以向其他服务器发起数据重建的任务并得到期望的数据。
3.3. 架构上的权衡
这一部分提出了一些在系统设计层面,为了解决长尾响应时间做的权衡:
- 更细粒度的Partition:为了解决系统负载不均衡,Google会将任务拆解成比机器数量多很多的Partition,这样,即使任务的复杂程度不同,机器的处理能力不同会导致各个机器的负载不均衡,这种不均衡也会大大降低。这就会带来系统的响应时间的一致性;
举例,如果一个系统有5台机器,将ABCDE 5个任务分给这5台机器来做,如果A任务很复杂,那分到A的机器处理时间就会变得很长。然而,如果将ABCDE 这5个任务继续拆分,变成 A1 - A10, B1-B10, …, D1-D10,再将这些任务分配到5台机器上去,那各台机器的负载就会平均很多(除非A1-A10全部分配到同一台机器上) - 对于热点的数据进行复制:如果某个新闻事件导致某个数据的访问量激增,则可以将该数据复制更多份,来降低这个热点数据的访问响应时间
- 将响应时间长的服务器暂时屏蔽:上游系统要实时监控所有下游服务器的响应时间,如果某台服务器的响应时间明显超过其他,则可以暂时将该服务器屏蔽(不再向这台服务器上发送请求),以提高整个系统的响应速度
- 某些情况不用追求完美:例如对于网页搜索服务,如果底层的某些系统出现故障,上层未必要等所有的响应全都返回,而是等待一段时间后,基于已经获得的数据为用户进行展示即可:good enough is better than high latency
4. 总结
这篇文章的要点总结完成,给我们的收获就是如果基于不确定的系统来实现确定的服务,本文的核心思想是
“A simple way to curb latency variability is to issue the same request to multiple replicas and use the results from whichever replica responds first.”
这个方法看似简单,然而在真正落地时还是会有很多的细节需要去权衡,大家可以通过读论文来学习Google是如何对各个细节进行权衡的。
论文原文:http://cacm.acm.org/magazines/2013/2/160173-the-tail-at-scale/fulltext