RocksDB 详解
性能好,支持事务。
秒杀库存扣减中使用了缓存 + Write-Ahead Logging 技术。
事务随机读写。Redo日志是追加文件顺序读写,性能差异有30-40倍。
事务的实现上,MySQL使用的是WAL机制来的。所有的修改都先被写到日志中,然后再被应用到系统重。包括
redo,undo.
RocksDB是Facebook开源的高性能,持久化的KV存储引擎,最初是Facebook数据库工程师团队基于 Google LevelDB开发。
一般很少使用到RocksDB保存数据。
越来越多的新生代数据库都选择RocksDB作为他们的存储引擎。比如:CockroachDB(蟑螂)一个开源,可伸缩,跨地域复制且
兼容事务的ACID特性的分布式数据库,思路来源于Google的全球性分布式数据库Spanner,其理念是将数据分布在多数据中心的
多台服务上。
YugabyteDB,Tidb 作为CockroachDB的竞争产品,底层也是RocksDB.
MyRocks使用RocksDB给MySQL做引擎,目的是取代现有的InnoDB存储引擎。MySQL的请兄弟MariaDB已经接纳了MyRocks作为
它的存储引擎。
实时计算引擎Flink,其State就是一个KV存储,它用的也是RocksDB
MongoDB,Cassandra,Hbase都在开发基于RocksDB的引擎。
原因是 RocksDB性能高,并且支持事务。
随机读写能达到: 18w-19w qps
覆盖操作能达到:9w tps
多读单鞋:10w qps
所以用RocksDB实现 Write-Ahead Logging
RocksDB为什么这么快呢
内存+磁盘IO,读写性能主要取决于他的存储结构。MySql B+树,Oracle B*,RocksDB LSM-tree
LSM-Tree
保证顺序写入的前提下,还能保证很好的查询性能。
WAL,跳表和一个分层的有序表(sorted String table,SSTable).LSM-Tree专门为key-value设计的
存储系统,以牺牲部分读性能为代价提高写入性能。通常适合于写多读上的场景。
LSM-Tree 描述图如下
在SSD搞并行下,扩展LevelDB以显示利用SSD的多通道,优化并发I/O请求的调度和调度策略,将常规SSD
上运行LevelDB的吞吐量再提高4倍。
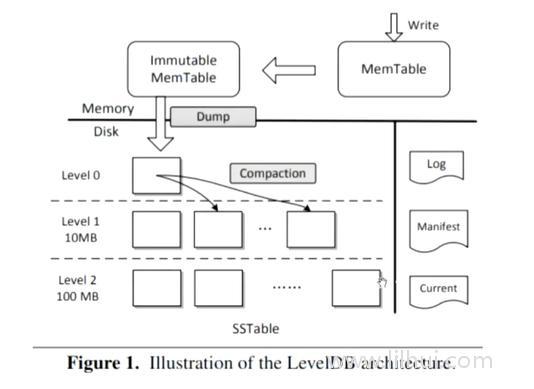
Log写入是使用的WAL机制,顺序写。
MemTable,跳表(类似红黑树)
c端过来写MemTable和log后就可以返回了。MemTable 32M,写满后会Dump成ImultableMemTable(不可变)
如果write继续,会重新创建一个MemTable.
问题:写入磁盘,部分有序全局无序。
解决方案:Level0,Level1,会进行合并。
SSTable分层,越热的数据越靠上。对热数据比较友好。