Reactor模型
- 管件类和概念
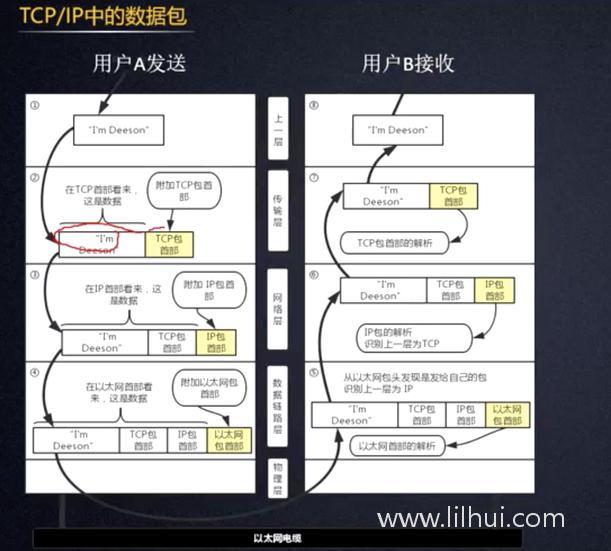
Channel, ChannelHandler,ChannelHandlerContext
ChannelHandler的执行规则 INBound,OutBound
Pipline里的ChannelHandlerContext
OutBoundHandler也有read,是为了校验,因为OutBound是在前面。
问题
outChannelHandler.write触发fireChannelRead的时候
inHandler会writeAndFlash,会触发outChannelHandler的 write形成死循环。
所以在OutHandler的write里不能fireChannelRead
会OverStackFlow
Bytebuf
Unpooled.xxx
- 申请方式
ByteBufAllocator heapBuffer() directBuffer()
compositeBuffer()
- 两套索引
readIndex和writeIndex
调用get* set不会移动索引。调用read, write*会移动相应的索引。
forEachByte 查找。
- 派生缓冲区
为Bytebuf提供了专门的方式来呈现其内容的试图。通过以下方法被创建:
dumplicate(), slice(), slice(int, int);
Unpooled.unmodifiableBuffer(…);
order(ByteOrder);
readSlice()
每个方法都返回一个新的ByteBuf实例,它具有自己的读索引、写索引和标记索引。
派生的缓冲区和原缓冲区的数据是共享的。
- 引用计数
release 计数减一。减到0后会进行回收。
减少GC。
池化的对象如果不释放,可能会引起内存溢出。
writeAndFlush会释放资源
SimpleChannelInboundHandler实现了 release。
- 粘包,半包
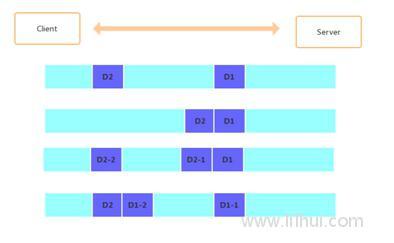
假设客户端分别发送了两个数据包D1和D2给服务器,由于服务器一次读取的字节数是不确定的。所以可能会有以下4种情况。
从用户空间到内存空间。累计几个包后进行flash一起发送。
1:服务端分两次读取到两个独立的数据包,分别是D1和D2,没有粘包和拆包。
2:服务端一次接收到了两个数据包,D1和D2粘在一起,被称为TCP粘包。
3:服务端分两次读取到了两个数据包,第一次读取到了完整的D1和D2部分内容,第二次读取到了D2的剩余内容。这个叫做TCP拆包。
4:服务端分两次读取到了两个数据包,第一次读取到了D1包的部分内容D1_1,第二次读取到了D1包剩余内容和D2包的完整包。
如果此时服务端TCP接收滑窗非常小,而数据D1和D2比较大,很有可能会发生第五种可能,既服务端分多次才能将D1和D2包接收完成。期间发生多次拆包。
- TCP粘包/半包发生的原因
TCP的Nagle算法,会合并小包,统一发送。如此,服务端无法区分哪些数据包是需要分开的,这就产生了粘包。
UDP:作为连接不可靠的传输协议。不会对数据包进行合并发送。没有Nogle算法。
UDP的包是 数据+UDP头+IP头一次封装,没有粘包。
分包产生的原因:
IP分片传输导致。传输过程丢失部分包。或者一个包被分成了多个,接收端顺序打乱了。
整理有几种情况:
1:数据大于套接字发送缓冲区。
2:进行MSS大小的TCP分段,MSS最大报文段长度的缩写。MSS是TCP报文段中数据段的最大长度。数据字段加上TCP首部才等于整个TCP报文段。所以MSS并不是TCP报文长度的最大长度。而是:MSS=TCP报文头长度-TCP首部长度。
1、两次请求,每个请求一个包
2、两次请求和成了一个包
3、第二个包被分成了两个包D2-2、D2-1 ,被分割的包D2-1的包有可能会跟D1合成一个包
4、第一个包分成了两个包,第二部分的包D1-2跟D2合成了一个包
- 如何解决粘包半包问题
1:包尾巴追加分隔符。 LineBasedFrameDecoder和DelimiterBasedFrameDecoder
2:消息定长。不够的补空格FixedLengthFrameDecoder
3:消息协议氛围消息头和消息体,消息头中包含标识消息总长度。通常设计思路为消息头的第一个字段使用int32来表示消息的总长度,LengthFieldBasedFrameDecoder。
- 编解码
加密解密\序列化 反序列化