- 分页查询优化详解。
- 表JOIN关联原理以及优化。
- 表COUNT查询优化。
- 阿里巴巴MYSQL规范解读。
- MYSQL数据类型选择分析。
分页查询优化
一般的分页:
select * from employee limit 1,100
- 优化方式:
根据自增连续主键排序的分页:
改成 id>xxx limit 10;用innerjoin来改写。
select * from employees order by name limit 90000,5可以改写成:
select * from employees e inner join(select id from employees order by name limit 90000,5) ed on e.id = ed.id
表JOIN关联
select * from t1 inner join t2 on t1.a = t2.a
在Mysql的实现中,Nested-Loop Join有3种实现的算法:
Simple Nested-Loop Join:SNLJ,简单嵌套循环连接
Index Nested-Loop Join:INLJ,索引嵌套循环连接
Block Nested-Loop Join:BNLJ,缓存块嵌套循环连接
嵌套循环链接 Nested-LoopJoin
Simple Nested-Loop
简单嵌套循环连接实际上就是简单粗暴的嵌套循环,如果table1有1万条数据,table2有1万条数据,那么数据比较的次数=1万 * 1万 =1亿次,这种查询效率会非常慢。
- Index Nested-Loop
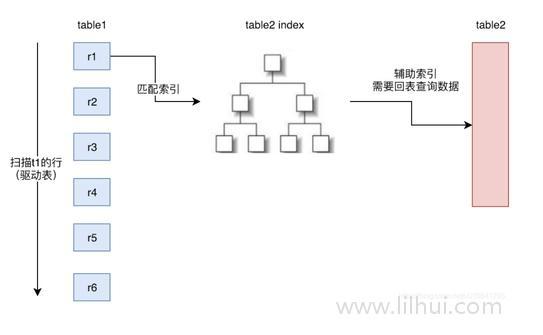
索引嵌套循环连接是基于索引进行连接的算法,索引是基于内层表的,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录进行比较, 从而利用索引的查询减少了对内层表的匹配次数,优势极大的提升了 join的性能:
使用场景:只有内层表join的列有索引时,才能用到Index Nested-LoopJoin进行连接。
由于用到索引,如果索引是辅助索引而且返回的数据还包括内层表的其他数据,则会回内层表查询数据,多了一些IO操作。
- 基于块的嵌套循环链接Block Nested-Loop Join算法
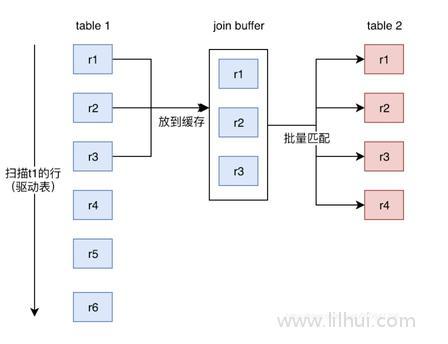
把驱动表的数据读入到join_buffer然后被驱动表扫描,与join_buffer的数据做对比。
极端条件下,会过滤 t1 数量 * t2 数量词。
缓存块嵌套循环连接通过一次性缓存多条数据,把参与查询的列缓存到Join Buffer 里,然后拿join buffer里的数据批量与内层表的数据进行匹配,从而减少了内层循环的次数(遍历一次内层表就可以批量匹配一次Join Buffer里面的外层表数据)。
当不使用Index Nested-Loop Join的时候,默认使用Block Nested-Loop Join。
什么是Join Buffer?
(1)Join Buffer会缓存所有参与查询的列而不是只有Join的列。
(2)可以通过调整join_buffer_size缓存大小
(3)join_buffer_size的默认值是256K,join_buffer_size的最大值在MySQL 5.1.22版本前是4G-1,而之后的版本才能在64位操作系统下申请大于4G的Join Buffer空间。
(4)使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认为开启。
- 优化JOIN
用小结果集驱动大结果集,减少外层循环的数据量,从而减少内层循环次数:
如果小结果集和大结果集连接的列都是索引列,mysql在内连接时也会选择用小结果集驱动大结果集,因为索引查询的成本是比较固定的,这时候外层的循环越少,join的速度便越快。为匹配的条件增加索引:争取使用INLJ,减少内层表的循环次数
增大join buffer size的大小:当使用BNLJ时,一次缓存的数据越多,那么内层表循环的次数就越少
减少不必要的字段查询:
(1)当用到BNLJ时,字段越少,join buffer 所缓存的数据就越多,内层表的循环次数就越少;
(2)当用到INLJ时,如果可以不回表查询,即利用到覆盖索引,则可能可以提示速度。(未经验证,只是一个推论
in和exsits优化
exists少用,能用join替代用join。
记住。小表驱动大表。
表COUNT执行
5.7版本 count(1),count(id),count(*)一样,几乎不用管。
分析:count(1) 不取值按行累加。count(*)也一样。count(字段) 拿出值走二级索引。count(id)走聚簇索引。
聚簇索引一般比二级索引大,所以count(字段有索引)比count(id)效率大一点点。
- 常见优化方法
维护表数据量。
innodb为什么不维护全表数量。是因为MVCC。多版本数据控制。不同的事务count(*)可能不一样。
count(*)
对总记录数没有特别精确可以用:
show table status like 'employees';
- redis维护。数据库缓存双写一致代价很高。
- 增加数据库计数表。
阿里巴巴Mysql规范手册解读
单标行不要超过500万行,或者单标容量超过2G,推荐分表。
如果预计三年后的数据量根本达不到这个级别,就不要在建表时就进行分表。
- 索引规约
- 有唯一键字段,即使是组合字段,也要建成唯一字段。
- 超过三个表不能进行join.
- 在varchar上建立索引,必须指定索引长度。
- 页面搜索严禁使用做模糊或者全模糊。这种场景适合走搜索引擎。
- 数据类型选择