索引优化
- 详解
- 优化索引选择探究
- 索引优化Orderby与Group byy
- UsingfileSort文件排序详解。
- 索引设计原则与实战。
索引优化原则
避免ALL权标扫描。即时没走索引也要避免回表
扫描行数不决定查询快慢,还有回表啊什么的影响。大多情况下不用去改mysql的优化查询。(force dindex 不一定会更快)
PS:
- 字符串不加单引号索引失效。
三个键的组合索引,范围查询放中间或者后面是可以走索引的。
强制走索引。扫描行数可能少了,但是执行时间并不一定减少。
覆盖索引优化。
in和or在表数量比较大的情况下回走索引,在表记录不多的情况下选择走权标扫描。
like kk%不管表数据量大小都会走索引。
概念:索引下推。like KK%就是用到了索引下推优化。
索引下推5.6引入的。
索引下推查询:在二级索引树过滤完like的字段后会再过滤后面条件的内容。符合的话进行会标。所谓的索引下面在推断。
非下推(5.6之前):在二级索引树过滤完like后没进行后面条件判断,直接回表,在回表的内容里在进行筛选。
索引下推意味着每次索引后,要再进行比对。like结果集少的话(like xxx%),比对就比较快。mysql会使用。如果数量非常大的话(column > xxx),每次都要比对,不一定比回表快。
使用 trace进行分析。列出explain sql执行的过程,mysql各个节点预估的消耗量。
优化总结
- mysql支持两种方式的排序filesort 和index, Using Index是指Mysql扫描索引本身完成排序,index效率高,filesort效率低。
- order by 满足两种情况会使用Using index
- order by语句使用索引最左前列。
- 使用where子句与order by子句条件组合满足索引最左前列。
- 尽量在索引列上完成排序,遵循索引建立的最左前缀法则。
- 如果 order by的条件不在索引列上,就会产生Using filesort
- 能用覆盖索引尽量用覆盖索引。
- group by 与order by很类似。其实质是先排序后分组,遵照索引创建顺序的最左前缀法则。对group by的优化如果不需要排序的可以加上order by null禁止排序。注意,where高于having,能卸载where先定条件就不要去having限定。
单路排序:
一次性取出满足条件行的所有字段,在sortbuffer中进行排序,用trace工具可以看到sort_mode信息显示。sort_key,additional_files或者 sort_key,packed_additional_fileds
不用回表。占用内存大。
双路排序:
根据条件取出相应的排序字段和可以直接定位行数据的ID,然后在sort buffer中进行爱旭。排序完后需要取回其他需要的字段、用trace工具可以看到sort_mode信息显示 sort_key,rowid。
需要回表,暂用内存小。
可设置max_length_for_sort_data默认1024 。如果参与排序的字段小于这个的话,使用单路排序。如果大于的话,会使用双路排序。一般不去设置。
sort_buffer 排序内存。如果它比较小的话可以适当把max_length_for_sort_data配置小点,让优化器选择双路排序。(双路排序用ID,不用tmpfile)
sort_buffer可以考虑配置更大的max_length_for_sort_data从而使用单路排序。
非DBA就不要去调整了。
怎么建索引
建完表后,一般主体的业务开发完后,把跟表相关的sql语句都拉出来。根据sql语句建索引。
原则:
- 代码先行,主体业务完成后,建索引。
- 联合索引尽量覆盖到你业务的所有查询。order by group by这些都需要考虑。
- 不要在小基数字段上建立索引。
- 长字符串可以采用前缀索引。varchar(255) 建索引耗费太大的空间,可以 Key index(name(20),age,position)。前缀的一部分进行建索引
- where 与order by冲突时优先where
- 基于慢sql查询进行建索引。slow_query_log=1
(provice,city,sex,age)
age一般范围查询,放后面,在实际查询中,查询可以把 sex按照in塞进去,这样age就可以走索引。一般一个组合索引里保持只有一个范围查询的字段。
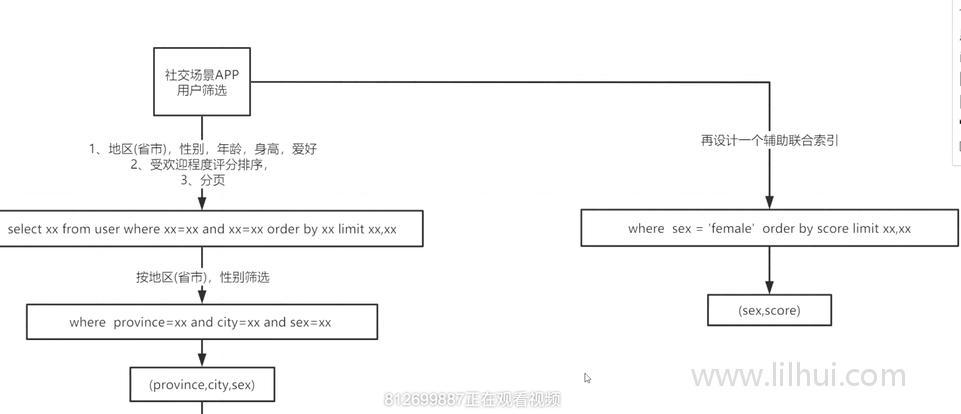
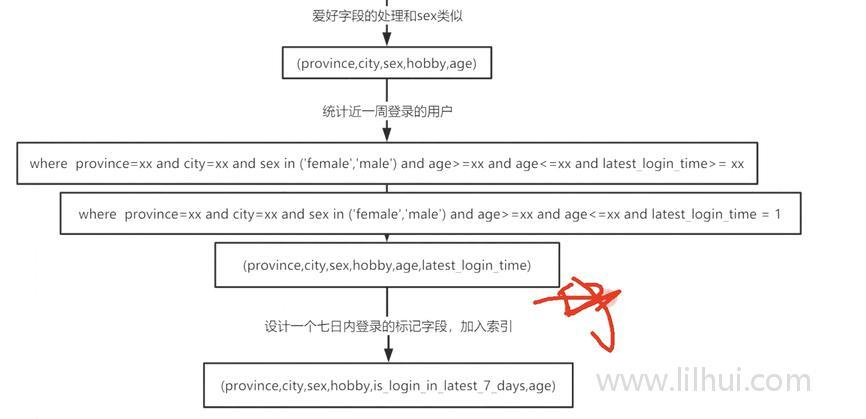
经验:10个字段左右的表。一个表里建2-3个组合二级索引就差不多了。