数据结构基础
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
数据结构
二叉树:可能产生单边链,对查询效率就很低。
红黑树:二插平衡树。 树的高度会很高。
B树:
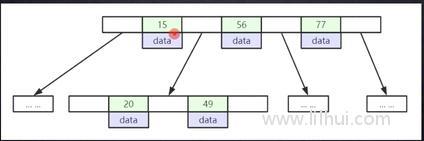
- 非叶子节点也有存data。一个元素占用1K。一个NODE最大 16个元素。
- 所以数量大的话,树高度也会很高。
PS:大概估计是1kb 总共能存16个元素
- B+树:
平衡,且树矮
索引的基本结构:B+树
- 非叶子节点不存储data,只存储所以。
- 叶子节点包含所有索引字段
- 叶子节点用指针连接。提高访问的性能。
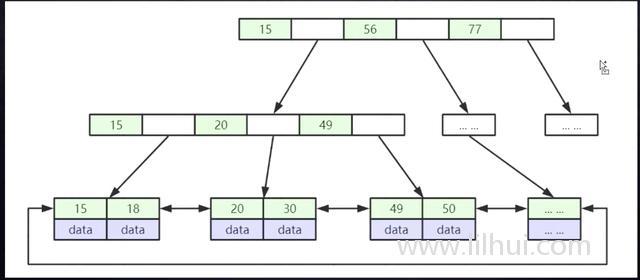
一个NODE(树的节点) 16K
按照页来分配,一个16K。
一次磁盘IO很慢,内存很快。所以比较费时间的是从磁盘node到NODE查询。
一个索引8B
一个地址6B
16KB可以放 16KB/(8+6)个元素1170
那么2层的B+tree
1170 * 1170 = 1368900
叶子节点有data一个NODE放16个元素。一个元素1K.
算上叶子节点 1170 * 1170 * 16
个元素。
大概2000多万。
树的高度3
所以只要3次IO。根节点常住内存。
存储引擎
mysam
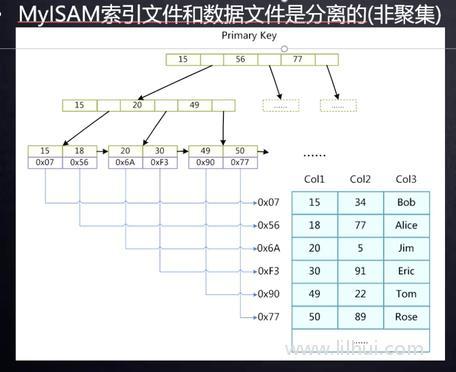
叶子节点存的数据地址。
innodb
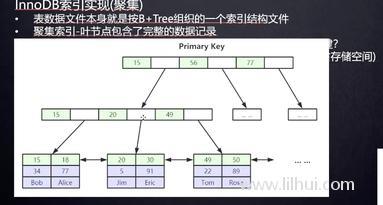
叶子节点存的是具体的data值。
索引类型
聚簇索引
MyInSam
ID主键是非聚簇索引。
Inodb
ID主键是聚簇索引。
关于主键
建立索引:
组织B+。如果没有索引的话,选择第一列所有元素都不相等的元素来组织。如果没找到,建立一个隐藏列。这个隐藏列是唯一ID 组织B+树。整型ID的作用:
在建立索引和查询索引的过程中,会进行多次的比大小。Int效率高。如果是String的话必须每个字符都要对比。并且占用空间也小,节省固态硬盘,节省成本。自增:
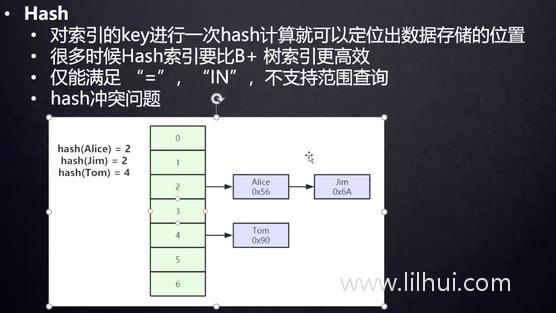
HASH索引下。很快可以对应到磁盘文件地址。
优点:等值查询很快。
缺点:范围查询效率不好。并且会产生HAHD冲突。聚簇索引和非聚簇索引那个快?
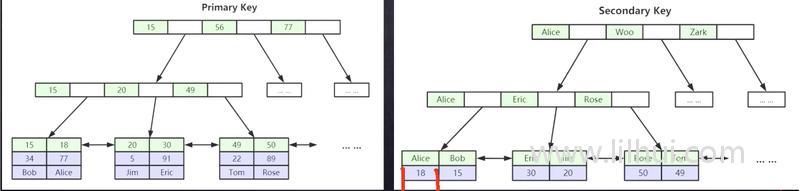
聚簇索引会比较快。非主键索引:
非聚簇索引的叶子节点的数据放的是聚簇索引索引节点值。
PS:INODB只有一个聚簇索引。
为什么不直接放数据?节约存储空间,可以多存放非常多数据。
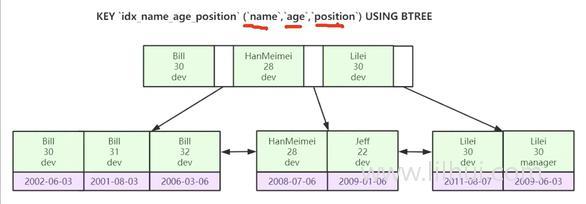
联合索引
联合索引底层存储
- 索引是帮助Mysql搞笑查询排好序的数据结构。
联合索引也是排好序的数据结构。